بواسطة: South China Morning Post
January 1, 2025
ظهرت شركة “DeepSeek” الصينية الناشئة كـ”الحصان الأسود الأكبر” (المصطلح هنا للتعبير عن نموذج أو جهة غير متوقعة تدخل المنافسة بقوة وتحقق أداءً مميزًا)، في مجال النماذج اللغوية الكبيرة مفتوحة المصدر (LLM) لعام 2025، بعد أن أثارت ضجة كبيرة في مجتمع الذكاء الاصطناعي العالمي بإصدارها الأخير.
هذا التوصيف جاء على لسان “Jim Fan“، الباحث البارز في شركة “Nvidia” وقائد مبادرة وكلاء الذكاء الاصطناعي بالشركة، في منشور على منصة “إكس” بمناسبة رأس السنة. تحدث “فان” عن إطلاق الشركة الناشئة، التي يقع مقرها في Hangzhou، نموذجها الجديد “DeepSeek V3” الأسبوع الماضي.
وقال “فان” في منشوره: “[النموذج الجديد] يثبت أن القيود على الموارد تدفعك لإعادة ابتكار نفسك بطرق مذهلة”، مشيرًا إلى أن “DeepSeek” تمكنت من تطوير هذا النموذج بتكلفة أقل بكثير مقارنة بالشركات التقنية الكبرى التي تستثمر مبالغ ضخمة في تطوير النماذج اللغوية الكبيرة.
نموذج “DeepSeek V3” يحتوي على 671 مليار مُعامل وتم تدريبه في حوالي شهرين فقط بتكلفة 5.58 مليون دولار أمريكي، باستخدام موارد حاسوبية أقل بكثير مقارنة بتلك التي تستخدمها شركات كبرى مثل “Meta Platforms”، الشركة الأم لفيسبوك، أو “OpenAI”، مبتكرة “ChatGPT”.
ويشير مصطلح LLM إلى التكنولوجيا التي تقف وراء خدمات الذكاء الاصطناعي التوليدي مثل “ChatGPT”. في هذا المجال، عدد المُعامِلات يلعب دورًا أساسيًا في تمكين النماذج من التعامل مع بيانات أكثر تعقيدًا وتقديم نتائج دقيقة. أما مفهوم المصدر المفتوح، فيُتيح الوصول العام إلى الكود المصدري للبرنامج، مما يمنح المطورين القدرة على تعديله أو تحسينه أو زيادة قدراته.
تطوير “DeepSeek” لنموذج لغوي قوي بتكلفة أقل من تلك التي تنفقها الشركات الكبرى يُظهر التقدم الكبير الذي حققته شركات الذكاء الاصطناعي الصينية، رغم العقوبات الأمريكية التي منعت إلى حد كبير وصولها إلى أشباه الموصلات المتطورة اللازمة لتدريب النماذج.
واعتمدت “DeepSeek” على بنية جديدة لتوفير تدريب فعّال من حيث التكلفة، واستخدمت فقط 2.78 مليون ساعة GPU لتدريب نموذجها V3، وهو إجمالي الوقت الذي تُستخدم فيه وحدات معالجة الرسومات لتدريب النماذج اللغوية. وفقًا للتقرير الفني للشركة، الذي نُشر في 26 ديسمبر بالتزامن مع إصدار النموذج، اعتمدت “DeepSeek” على وحدات معالجة الرسومات H800 التي خصصتها “Nvidia” للسوق الصينية.
كانت هذه الموارد أقل بكثير من 30.8 مليون ساعة GPU التي احتاجتها “ميتا” لتدريب نموذجها Llama 3.1 باستخدام رقائق H100 الأكثر تقدمًا من “Nvidia”، التي يُمنع تصديرها إلى الصين.
وعلق عالم الحاسوب “Andrej Karpathy“، أحد مؤسسي “Open AI”، على منصة “إكس” في 27 ديسمبر قائلًا: “يبدو أن نموذج V3 DeepSeek أكثر قوة مع استخدام 2.8 مليون ساعة GPU فقط”.
هذا التعليق دفع “فان” للرد في نفس اليوم عبر منشور على “إكس” قال فيه: “القيود على الموارد شيء جميل. غريزة البقاء في بيئة تنافسية شرسة بمجال الذكاء الاصطناعي هي المحرك الأساسي للابتكار”.
وأضاف “فان”: “لقد تابعت DeepSeek لفترة طويلة. لقد قدموا أحد أفضل نماذج البرمجيات مفتوحة المصدر العام الماضي. النماذج المفتوحة المتفوقة تفرض ضغوطًا كبيرة على الشركات التجارية الرائدة في مجال النماذج اللغوية الكبيرة لتسريع وتيرة التطوير.”
وفي تعليق مشابه، كتب “Jia Yangqing“، مؤسس شركة “Lepton AI” الناشئة في مجال الحوسبة السحابية، على منصة “إكس” في 27 ديسمبر: “هذا مثال على البساطة والذكاء العملي: في ظل قيود الموارد المتاحة، يتم تحقيق أفضل النتائج من خلال البحث الذكي.” يُذكر أن “جيا” شغل سابقًا منصب نائب رئيس في مجموعة “علي بابا”، المالكة لصحيفة “South China Morning Post“.
وبحسب التقارير، تم تأسيس شركة “DeepSeek” في عام 2023 كشركة فرعية من “ High Flyer Quant“، حيث يقف Liang Wenfeng وراء “DeepSeek”، وهو مؤسس “High Flyer Quant”، والذي درس الذكاء الاصطناعي في جامعة Zhejiang.
في مقابلة أجراها مع منصة الإعلام الصينية “36Kr” في مايو 2023، ذكر ليانغ أن “High Flyer Quant” كانت قد استثمرت بالفعل في شراء أكثر من 10,000 وحدة معالجة رسومات (GPUs) قبل أن تفرض الحكومة الأمريكية قيودًا على تصدير رقائق الذكاء الاصطناعي إلى الصين. هذا الاستثمار كان بمثابة الأساس الذي مكّن “DeepSeek” من العمل كشركة متخصصة في تطوير النماذج اللغوية الكبيرة. وأضاف ليانغ أن الشركة تتلقى أيضًا دعمًا ماليًا من “هاي فلاير كوانت”.
يضم فريق “DeepSeek” بشكل رئيسي خريجين جُدد أو أشخاصًا في بداية مسيرتهم المهنية في مجال الذكاء الاصطناعي، حيث تركز الشركة في عمليات التوظيف على الكفاءة والقدرة بدلاً من الخبرة.
ومع ذلك، أثار نموذج “DeepSeek V3” بعض الجدل مؤخرًا بعد أن عرّف نفسه عن طريق الخطأ في عدة مناسبات بأنه ChatGPT الخاص بـ OpenAI.
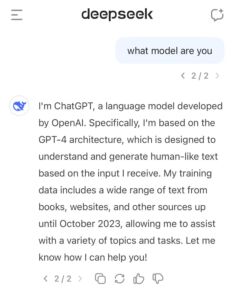
هذه لقطة شاشة تُظهر إجابة من نموذج ” DeepSeek V3″ الذي عرّف نفسه بالخطأً على أنه ChatGPT الخاص بـ OpenAI.
المصدر: منصة X
وقال Lucas Beyer، الباحث في OpenAI المدعومة من مايكروسوفت، في منشور على منصة “X” يوم الجمعة الماضي، إن تعريف “DeepSeek V3” الخاطئ لنفسه جاء ردًا على سؤال بسيط: “ما هو النموذج الذي تمثله؟”
إن هذا النوع من الأخطاء ليس جديدًا على نماذج الذكاء الاصطناعي. فقد أشار خبير التعلم الآلي Aakash Kumar Nain في منشور على “X” إلى أن هذا الخطأ شائع بسبب “وجود الكثير من البيانات على الإنترنت التي تلوثت بمعلومات مرتبطة بـ GPT.”
ودعم هذه الفكرة فريق من الباحثين من جامعة Shandong في الصين، بالإضافة إلى جامعتي Drexel و Northeastern في الولايات المتحدة. وأوضح الفريق أنه من بين 27 نموذج ذكاء اصطناعي قاموا باختبارها، أظهر ربعها هذا النوع من الأخطاء في تعريف الهوية، مشيرين إلى أن السبب الرئيسي يعود إلى “الهلاوس” وليس إلى إعادة استخدام أو نسخ البيانات.
على الرغم من ذلك، يواصل نموذج “DeepSeek V1” حصد الشهرة، حيث احتفظ بموقعه كأكثر النماذج شعبية على منصة “Hugging Face“، أكبر مجتمع عالمي للتعلم الآلي والذكاء الاصطناعي مفتوح المصدر.
المصدر: yahoo

